 Skip to content
Skip to content







Categories
Tags
Newsletter
Subscribe to the QRP International neswletter and get all the news on trends, useful contents and invitations to our upcoming events
Subscribe
As we all know, the end of the 1980’s did not only see the Guns N’ Roses reach stardom, the first world tours of Madonna and Michael Jackson but, (arguably) more importantly, the appearance of ITIL. Thanks to this new framework, IT is now providing Services (instead of technology) to their users and customers, and everybody agrees that disruptions of Service are bad and should be resolved as soon as possible. We will come back later on these two aspects, and we will see how they are the source of all evil.
The issue might appear as it should be addressed by a psychologist instead of an IT person : we, human beings, find enormous difficulties in leaving an obvious pain unaddressed, even for the promise of later improvement. If you think about it, this is the origin of our catch 22 (catch 22; a paradoxical situation from which an individual cannot escape because of contradictory rules or limitations.)
When implementing the ITIL best practices in an organization, we set up Practices (used to be named Processes) because we want to:
Even though the ultimate goal of all Practices is to make our customers happy, some of them are more user-facing than others. This is where we get into trouble : we invest all our resources in the most user-facing Practices, which leaves us unarmed when we should invest time and energy is less user-facing but equally (or even more) important Practices.
Putting focus on the most user-facing Practices is an obvious choice. When users are putting the Service Desk under pressure, or when an Incident impacts production, or when customers are waiting behind your door for the next version of your Product, you want to undertake action. It is humanly very difficult (in some situations, I daresay even impossible) to push back these activities in favour of others that will not have an immediate effect.
As a result, we end-up investing all our time and energy in fighting fires, in such a way that we do not have the possibility to ask ourselves why we are having so many fires to begin with. And here we find our catch 22 : interruptions of Service (Incidents) are bad and should be resolved as quickly as possible. We put so much focus on the second part of the sentence that we forget the first one. If we agree that Incidents are bad, that they have a very negative impact on customer satisfaction, then we should try to avoid them, should we not? And if we cannot avoid them completely, try to minimize their impact, as is the goal of Problem Management. We all agree on this, but it is easier said than done, because we are only human and so engulf in the “resolved as quickly as possible” part of the sentence.
So this is it, there is no way out, really? Are we condemned to empty this barrel without ever being able to turn off the tap that is filling it? Well, hopefully not. But as I said, there is no magic solution. Or at least none that I know of (if you have one handy, do not hesitate to share it with us). But we can work at it, and reduce the flow of the faucet.
In an ideal world, one might think, an organization should have two separate teams to work on Incidents and Problems, so as to avoid being sucked in the catch 22 mentioned above. However, things are, unfortunately, not that simple.
Incidents and Problems are closely linked
The first reason that comes to mind to justify the impossibility for separate teams, is because we do not have enough manpower to dedicate a team solely to resolving Problems. If this is true in most of the situations, we would probably not strictly separate these two activities anyway, because they are closely linked.
Indeed, the technical knowledge and skills required are cross-practices. One learns a lot of useful things to troubleshoot Problems and document Workarounds as one is working on Incidents, and the other way around. So totally segregated groups is probably not the best answer. But temporary teams might be. Indeed, setting up a temporary team (including the right skills) to work on one or several Problems should spare the member of the team the pressure oozing from Incident Management under the condition that the temporary team can work in a dedicated location.
Clear implementation of the three phases of Problem Management
A clear implementation of the three phases of Problem Management, as suggested in ITIL 4, can also help you move in the right direction. As each phase has a clearly defined output, it is relatively easy to entrust the different phases to different groups, which can also be a good way to spread the workload and so find the time that we sorely miss.
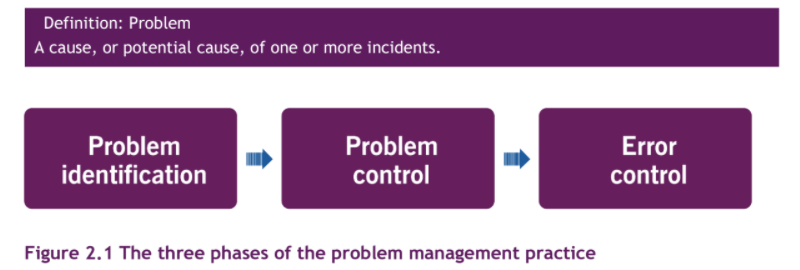
1. The Problem Identification phase, both proactive and reactive, should, to my opinion, be performed by people with both technical and functional skills. They should have a good understanding of the organization, as well as a clear vision of the technical infrastructure our services rely upon. Both are necessary to spot existing and potential Problems and thus produce the required output : complete and well documented Problem records.
A prioritization of the Problems records should take place between the Problem Identification phase and the Problem Control phase. This is essential to reduce pressure (there is always too much to do) and ensure that we make the best possible usage of our limited resources.
2. The Problem Control phase should be executed by creative, broad-thinking, experienced technicians. Starting from Problem records, they analyse the Problems and document their findings. This will bring the Problems to the status of Known Error. Expected output of this second phase are Workaround solutions, that will help resolve Incidents quicker (and thus improve user satisfaction and free some time of our technical staff, starting to see the end of the catch 22).
3. Error Control is the third and last phase of the Problem Management Practice. An important activity of this phase is once again one of prioritization. As Known Errors can stay open for quite a while, and that circumstances are bound to change, this prioritization activity should take place on a regular basis. Known Errors priority should be evaluated by a team of people. Indeed, several criteria must be taken into account like :
Once Known Errors are prioritized, work can begin on definitive resolution or on Workaround improvement.
Hopefully this structured approach of Problem Management will inspire you enough so that you can adapt it to your own organization, and so get out of “the catch 22 of Problem Management”.
